|
Xiang Li 李希昂
Member of Technical Stuff
xAI,
Bellevue, WA.
Email: xli@xai.com
|

|
I am a Member of Technical Stuff at xAI. I was a research scientist at Google DeepMind working on Veo project (Veo2, Veo3, Veo4). I got my PhD from Carnegie Mellon University advised by Prof. Bhiksha Raj. My research interest lies on the representation learning for media generation and understanding.
News
[08/2025] One paper accepted to EMNLP 2025 (findings).
[05/2025] One paper accepted to ICML 2025.
[02/2025] One paper accepted to CVPR 2025.
[01/2025] Two papers (one first-author) accepted to ICLR 2025.
[09/2024] Three papers accepted to NeurIPS 2024.
[06/2024] One first-author paper accepted to ECCV 2024.
[06/2024] One paper accepted to InterSpeech 2024.
[05/2024] Two papers (one first-author) accepted to ICML 2024.
[03/2024] One paper accepted to NAACL 2024.
[02/2024] One first-author paper accepted to CVPR 2024.
[12/2023] One paper accepted to ICASSP 2024.
[10/2023] One first-author paper accepted to EMNLP 2023.
[09/2023] One first-author paper accepted to NeurIPS 2023.
[06/2023] One first-author paper accepted to ICCV 2023.
[06/2023] One first-author paper accepted to ACM MM 2023.
Publications
|
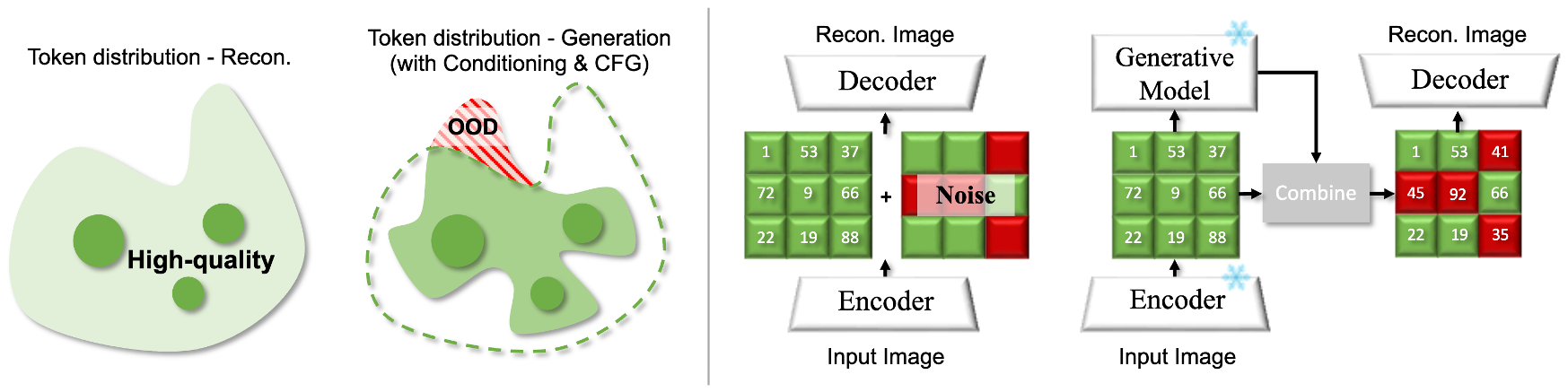
Image Tokenizer Needs Post Training
Kai Qiu*, Xiang Li*, Hao Chen, Jason Kuen, Xiaohao Xu, Jiuxiang Gu, Yinyi Luo, Bhiksha Raj, Zhe Lin, Marios Savvides
Preprint 2025
[paper]
[project page]
|
|
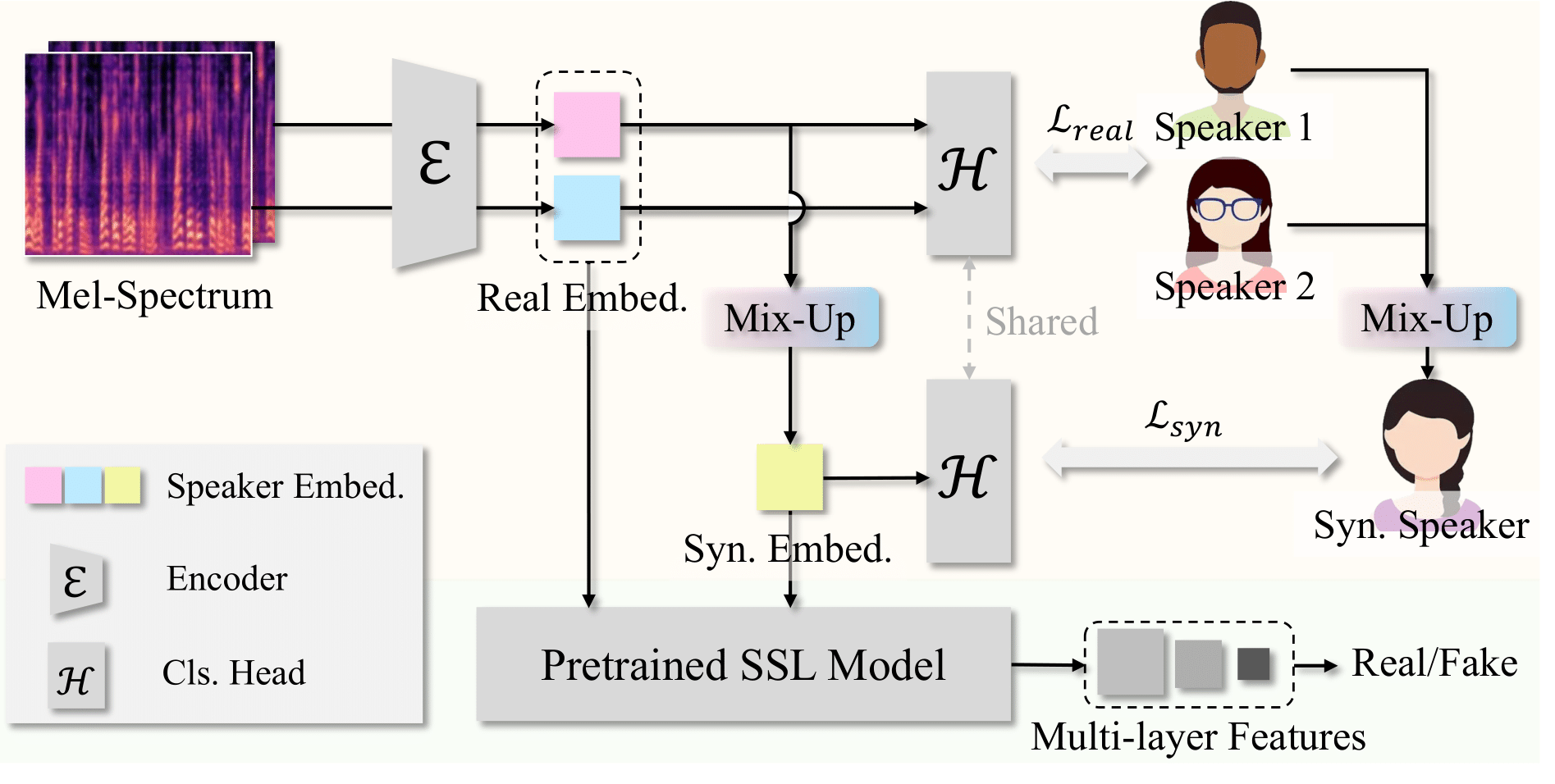
CAARMA: Class Augmentation with Adversarial Mixup Regularization
Massa Baali, Xiang Li, Hao Chen, Rita Singh, Bhiksha Raj
EMNLP 2025 (Findings)
[paper]
[code]
|

|
Robust Latent Matters: Boosting Image Generation with Sampling Error Synthesis
Kai Qiu*, Xiang Li*, Jason Kuen, Hao Chen, Xiaohao Xu, Jiuxiang Gu, Yinyi Luo, Bhiksha Raj, Zhe Lin, Marios Savvides
preprint
[paper]
[code]
|

|
Towards Ambiguity-Free Spatial Foundation Model: Rethinking and Decoupling Depth Ambiguity
Xiaohao Xu, Feng Xue, Xiang Li, Haowei Li, Shusheng Yang, Tianyi Zhang, Matthew Johnson-Roberson, Xiaonan Huang
preprint
[paper]
[code]
|
|
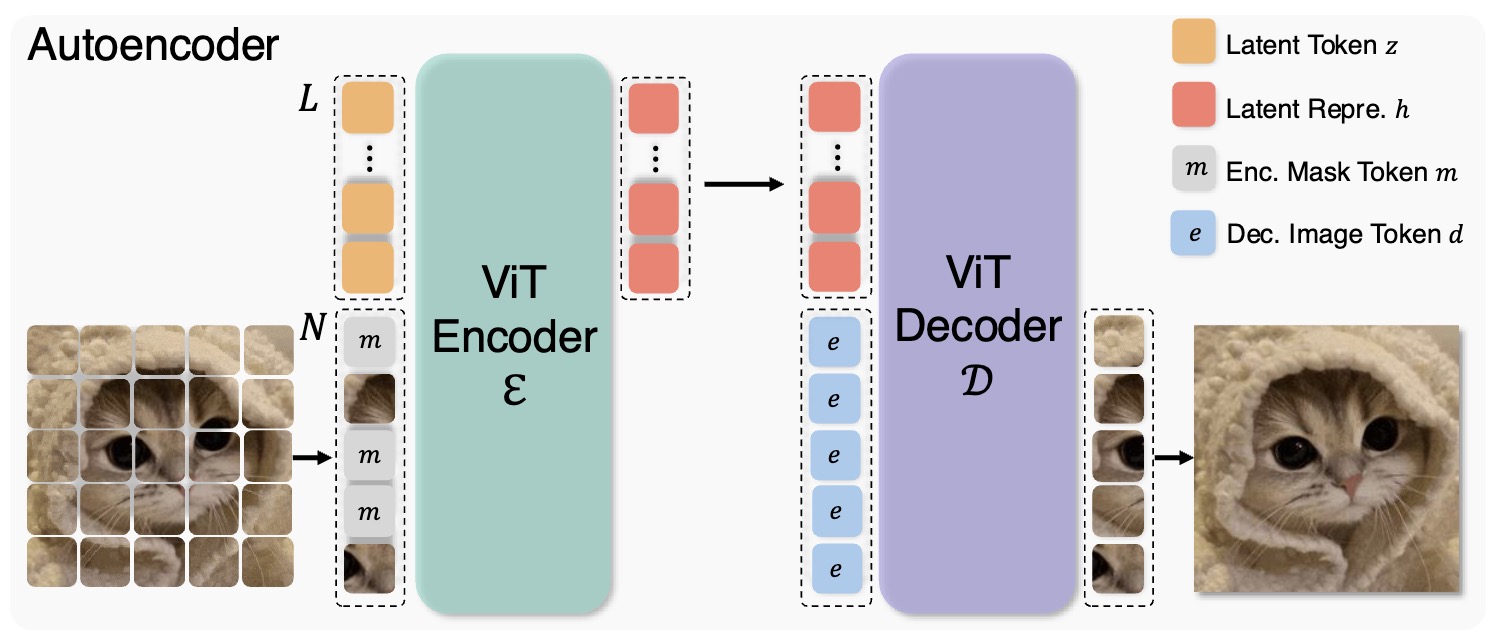
Masked Autoencoders Are Effective Tokenizers for Diffusion Models
Hao Chen, Yujin Han, Fangyi Chen, Xiang Li, Yidong Wang, Jindong Wang, Ze Wang, Zicheng Liu, Difan Zou, Bhiksha Raj
ICML 2025
[paper]
[code]
|
|
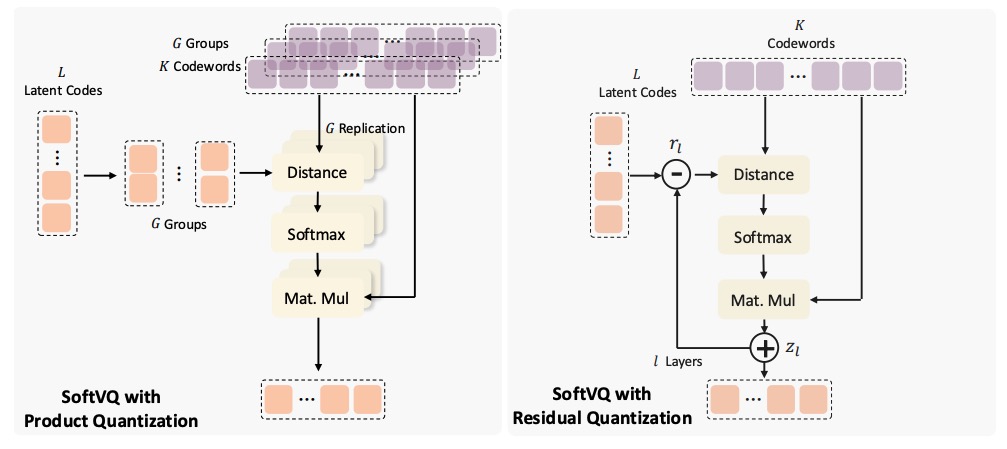
SoftVQ-VAE: Efficient 1-Dimensional Continuous Tokenizer
Hao Chen, Ze Wang, Xiang Li, Ximeng Sun, Fangyi Chen, Jiang Liu, Jindong Wang, Bhiksha Raj, Zicheng Liu, Emad Barsoum
CVPR 2025
[paper]
[code]
|
|
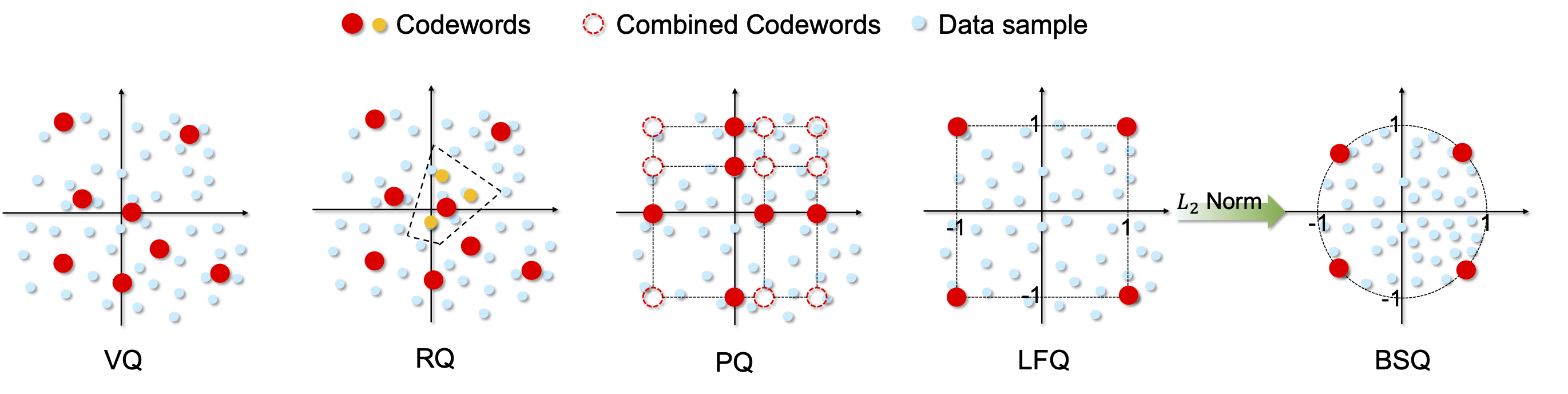
XQ-GAN: An Open-source Image Tokenization Framework for Autoregressive Generation
Xiang Li*, Kai Qiu*, Hao Chen, Jason Kuen, Jiuxiang Gu, Bhiksha Raj, Zhe Lin
preprint
[paper]
[code]
|
|
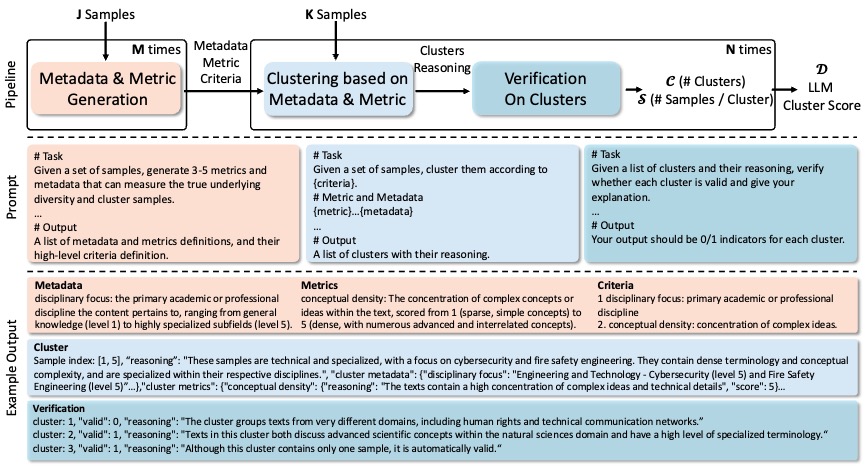
On the Diversity of Synthetic Data and its Impact on Training Large Language Models
Hao Chen, Abdul Waheed, Xiang Li, Yidong Wang, Jindong Wang, Bhiksha Raj, Marah I Abdin
preprint
[paper]
|
|
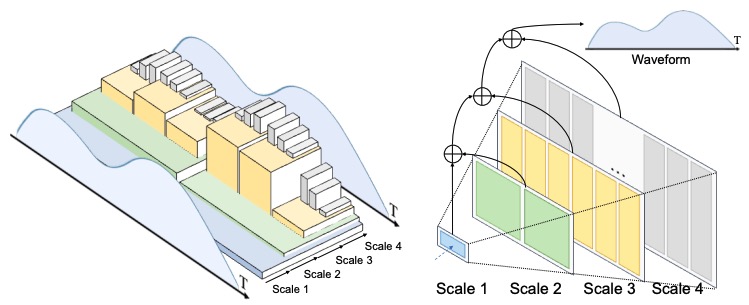
Efficient Autoregressive Audio Modeling via Next-Scale Prediction
Kai Qiu, Xiang Li, Hao Chen, Jie Sun, Jinglu Wang, Zhe Lin, Marios Savvides, Bhiksha Raj
preprint
[paper]
[code]
|
|
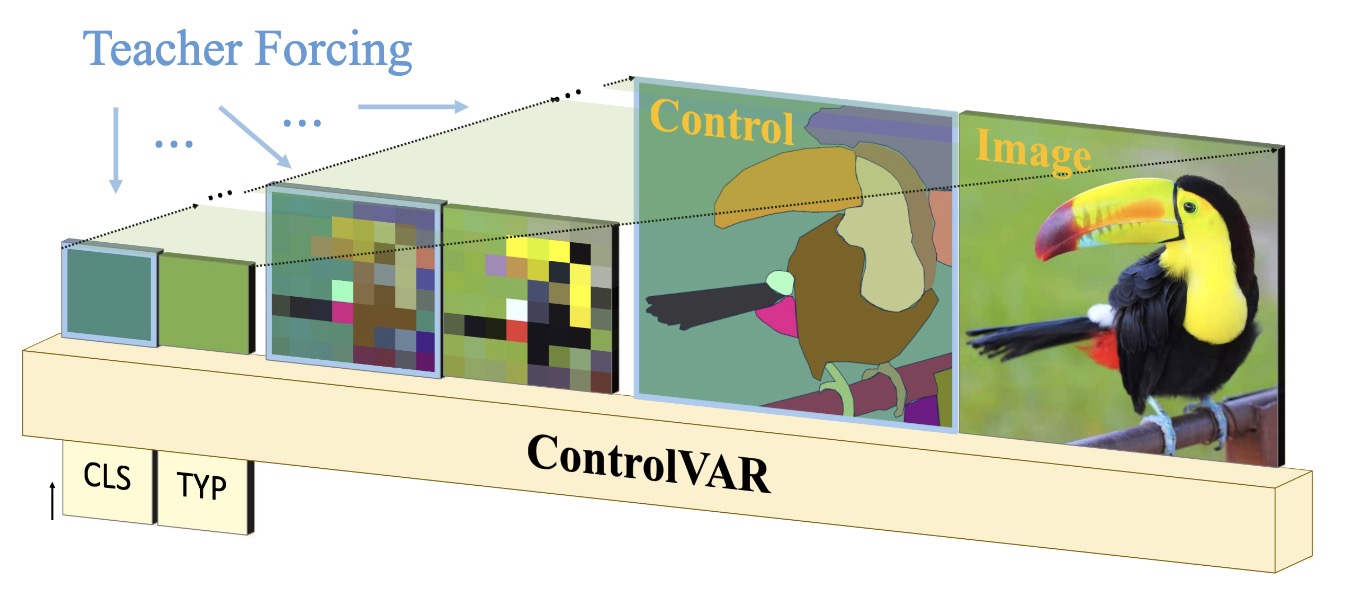
ControlVAR: Exploring Controllable Visual Autoregressive Modeling
Xiang Li, Kai Qiu, Hao Chen, Jason Kuen, Zhe Lin, Rita Singh, Bhiksha Raj
preprint
[paper]
[code]
|
|
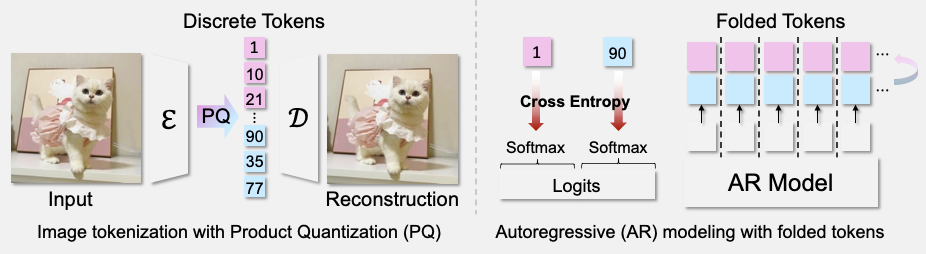
ImageFolder: Autoregressive Image Generation with Folded Tokens
Xiang Li, Hao Chen, Kai Qiu, Jason Kuen, Jiuxiang Gu, Bhiksha Raj, Zhe Lin
ICLR 2025
[paper]
[code]
[project page]
|
|
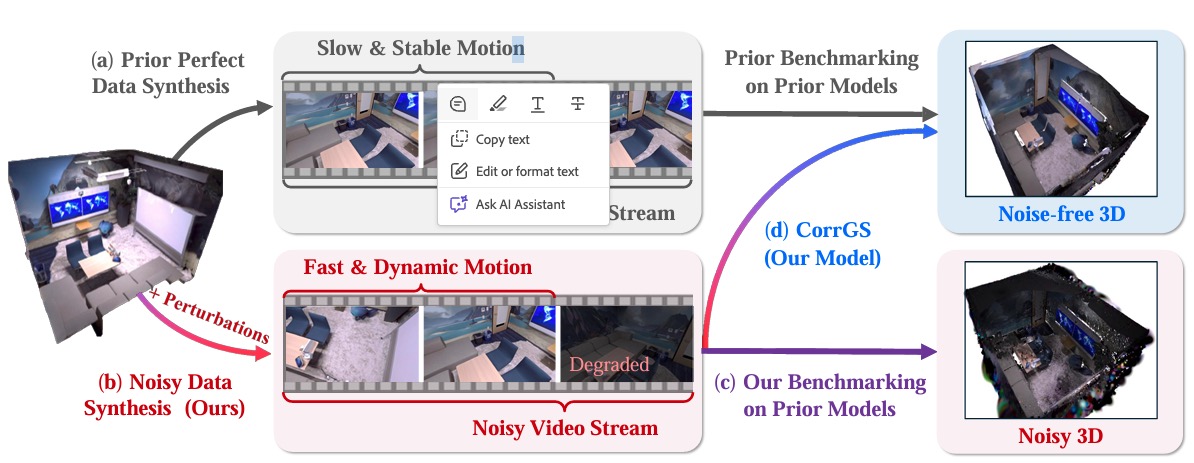
Scalable Benchmarking and Robust Learning for Noise-Free Ego-Motion and 3D Reconstruction from Noisy Video
Xiaohao Xu, Tianyi Zhang, Shibo Zhao, Xiang Li, Sibo Wang, Yongqi Chen, Ye Li, Bhiksha Raj, Matthew Johnson-Roberson, Sebastian Scherer, Xiaonan Huang
ICLR 2025
[paper]
|
|
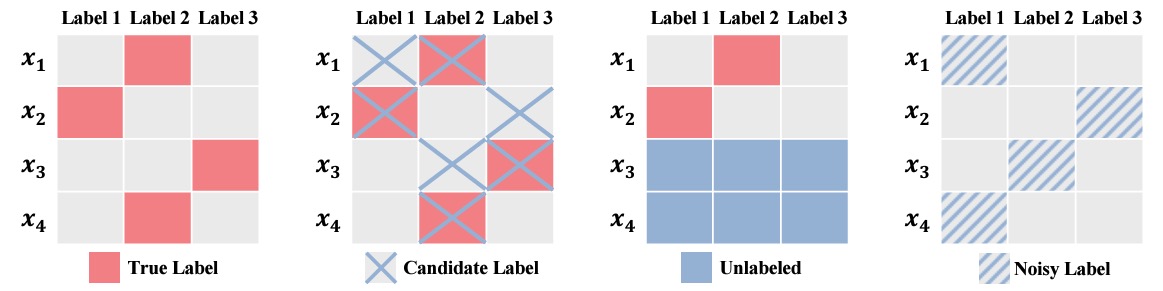
Imprecise Label Learning: A Unified Framework for Learning with Various Imprecise Label Configurations
Hao Chen, Ankit Shah, Jindong Wang, Ran Tao, Yidong Wang, Xiang Li, Xing Xie, Masashi Sugiyama, Rita Singh, Bhiksha Raj
NeurIPS 2024
[paper]
|

|
Slight Corruption in Pre-training Data Makes Better Diffusion Models
Hao Chen, Yujin Han, Diganta Misra, Xiang Li, Kai Hu, Difan Zou, Masashi Sugiyama, Jindong Wang, Bhiksha Raj
NeurIPS 2024
[paper]
|

|
Efficient LLM Jailbreak via Adaptive Dense-to-sparse Constrained Optimization
Kai Hu, Weichen Yu, Tianjun Yao, Xiang Li, Wenhe Liu, Lijun Yu, Yining Li, Kai Chen, Zhiqiang Shen, Matt Fredrikson
NeurIPS 2024
[paper]
|
|
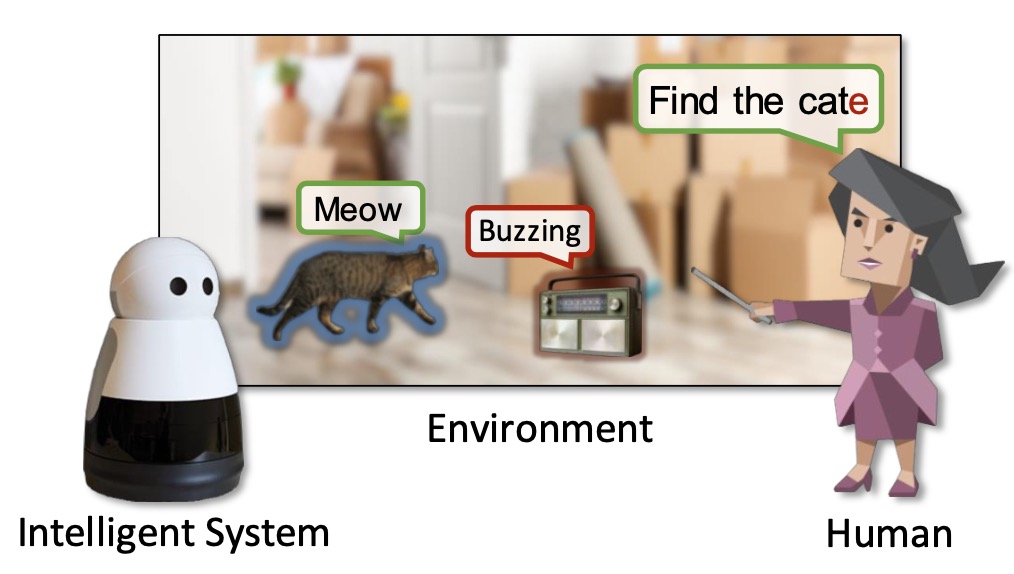
R^2-Bench: Benchmarking the Robustness of Referring Perception Models under Perturbations
Xiang Li, Kai Qiu, Jinglu Wang, Xiaohao Xu, Rita Singh, Kashu Yamazaki, Hao Chen, Xiaonan Huang, Bhiksha Raj
ECCV 2024
[paper]
[code]
|
|
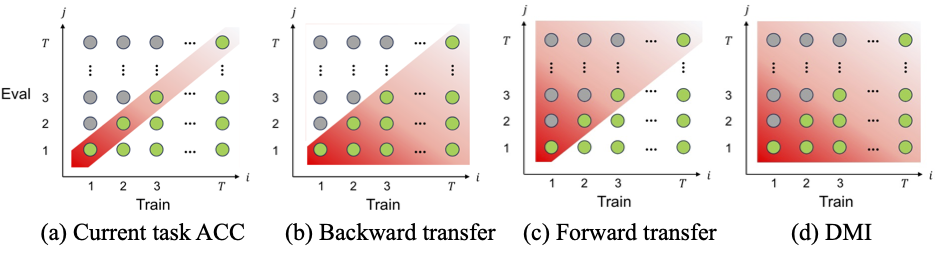
Evaluating and Improving Continual Learning in Spoken Language Understanding
Muqiao Yang, Xiang Li, Umberto Cappellazzo, Shinji Watanabe, Bhiksha Raj
InterSpeech 2024
[paper]
|
|
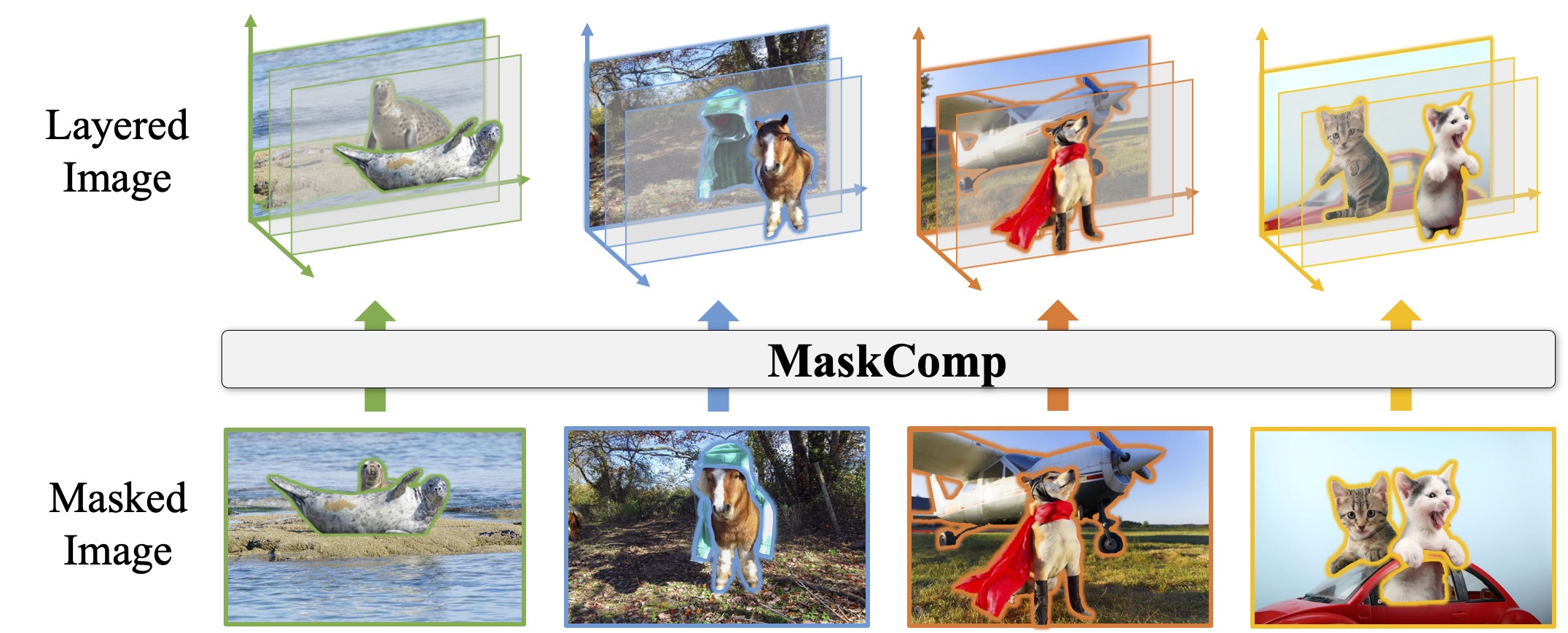
Completing Visual Objects via Bridging Generation and Segmentation
Xiang Li, Yinpeng Chen, Chung-Ching Lin, Rita Singh, Bhiksha Raj, Zicheng Liu
ICML 2024
[paper]
|
|
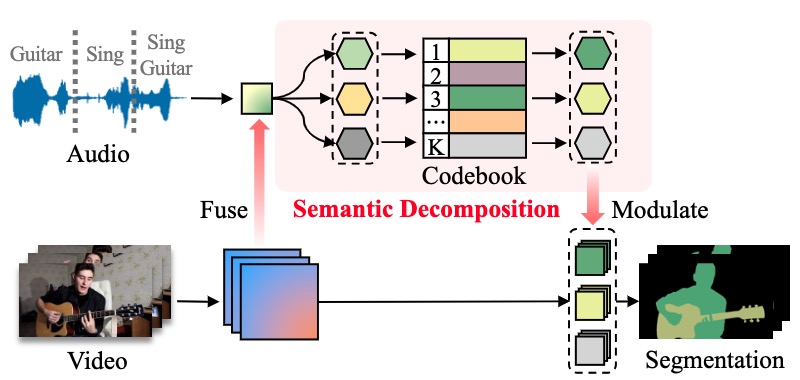
Rethinking Audiovisual Segmentation with Semantic Quantization and Decomposition
Xiang Li, Jinglu Wang, Xiaohao Xu, Rita Singh, Yan Lu, Bhiksha Raj
CVPR 2024
[paper]
[code]
|
|
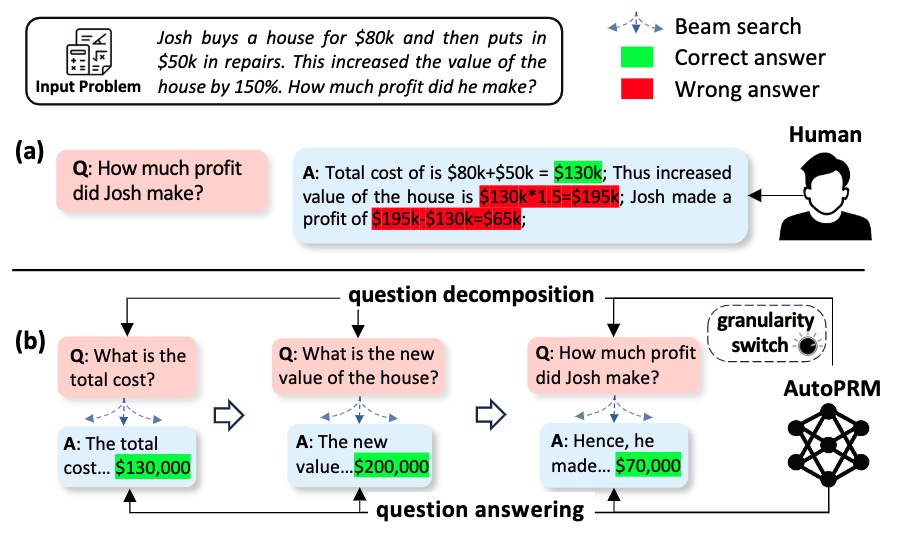
AutoPRM: Self-supervised Fine-grained Feedback for Multi-Step Reasoning via Controllable Question Decomposition
Zhaorun Chen, Zhuokai Zhao, Zhihong Zhu, Ruiqi Zhang, Xiang Li, Bhiksha Raj, Huaxiu Yao
NAACL 2024 (short version at ICLR 2024 R2-FM workshop)
[paper]
|
|
A General Framework for Learning from Weak Supervision
Hao Chen, Jindong Wang, Lei Feng, Xiang Li, Yidong Wang, Xing Xie, Masashi Sugiyama, Rita Singh, Bhiksha Raj
ICML 2024
[paper]
|
|
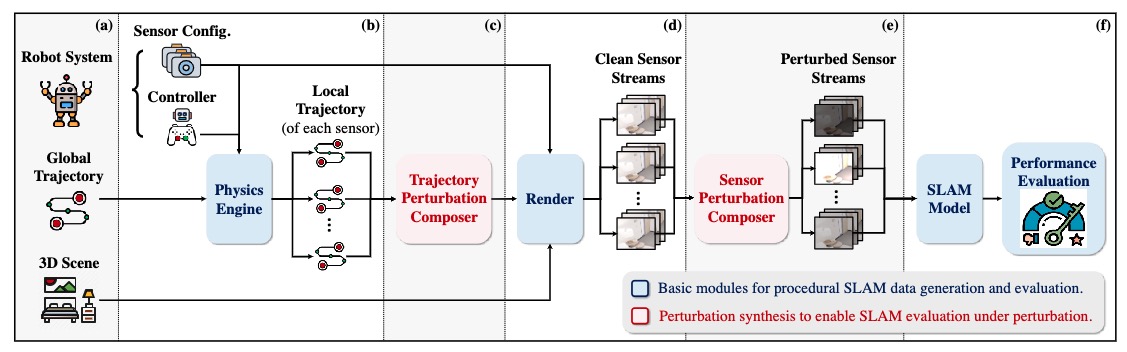
Customizable Perturbation Synthesis for Robust SLAM Benchmarking
Xiaohao Xu, Tianyi Zhang, Sibo Wang, Xiang Li, Yongqi Chen, Ye Li, Bhiksha Raj, Matthew Johnson-Roberson, Xiaonan Huang
preprint
[paper]
[code]
|
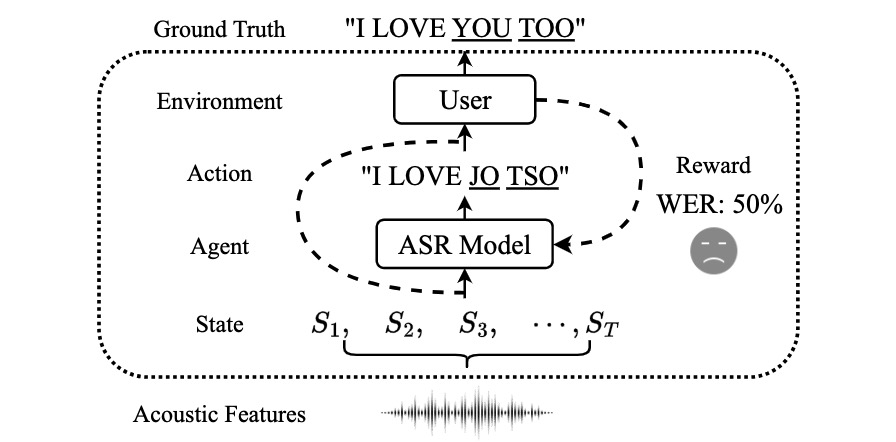
|
A Closer Look at Reinforcement Learning-based Automatic Speech Recognition
Fan Yang, Muqiao Yang, Xiang Li, Yuxuan Wu, Zhiyuan Zhao, Bhiksha Raj, Rita Singh
Computer Speech & Language
[paper]
|
|
Improving Continual Learning of Acoustic Scene Classification via Mutual Information Optimization
Muqiao Yang, Umberto Cappellazzo, Xiang Li, Shinji Watanabe, Bhiksha Raj
ICASSP 2024
[paper]
|
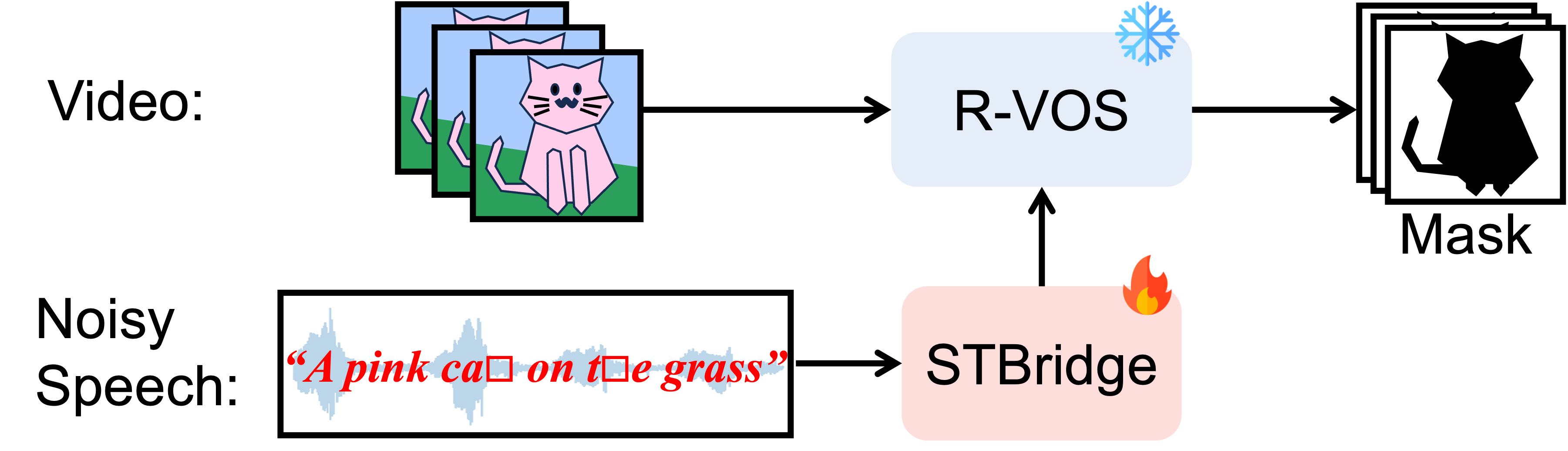
|
Towards Noise-Tolerant Speech-Referring Video Object Segmentation:
Bridging Speech and Text
Xiang Li, Jinglu Wang, Xiaohao Xu, Muqiao Yang, Rita Singh, Bhiksha Raj
EMNLP 2023
[paper]
|
|
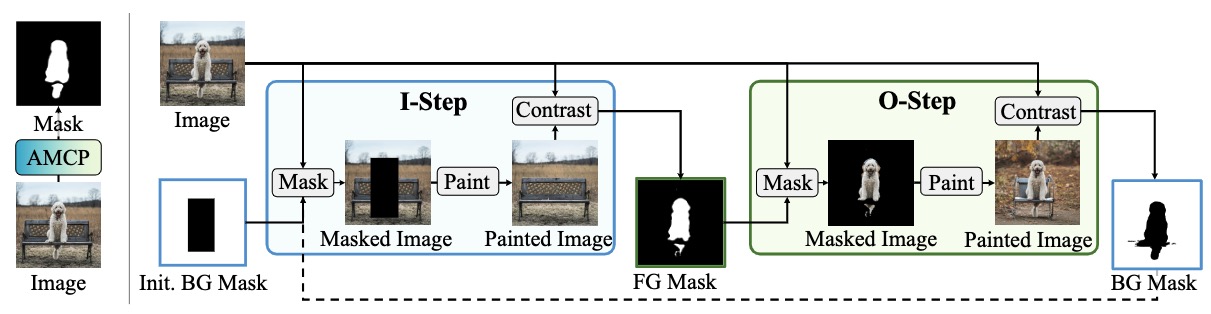
PaintSeg: Training-free Segmentation via Painting
Xiang Li, Chung-Ching Lin, Yinpeng Chen, Jinglu Wang, Zicheng Liu, Bhiksha Raj
NeurIPS 2023
[paper]
[code]
|
|
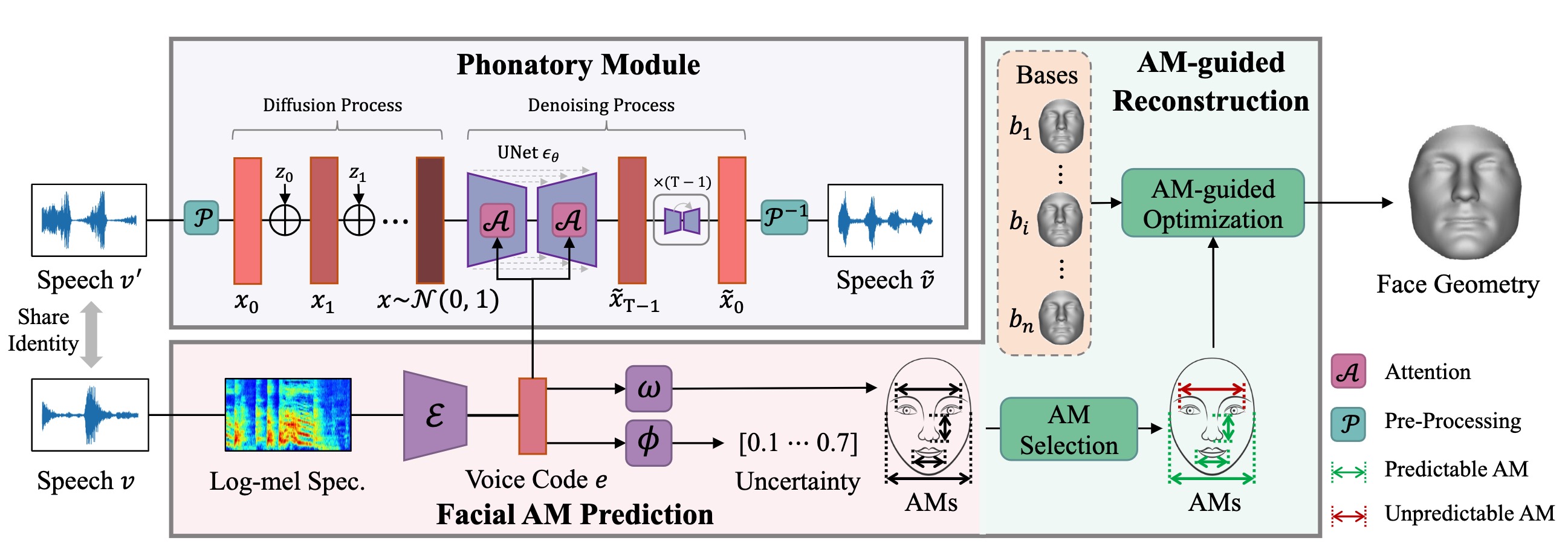
Rethinking Voice-Face Correlation: A Geometry View
Xiang Li, Yandong Wen, Muqiao Yang, Jinglu Wang, Rita Singh, Bhiksha Raj
ACM Multimedia, 2023
[paper]
[code]
|
|
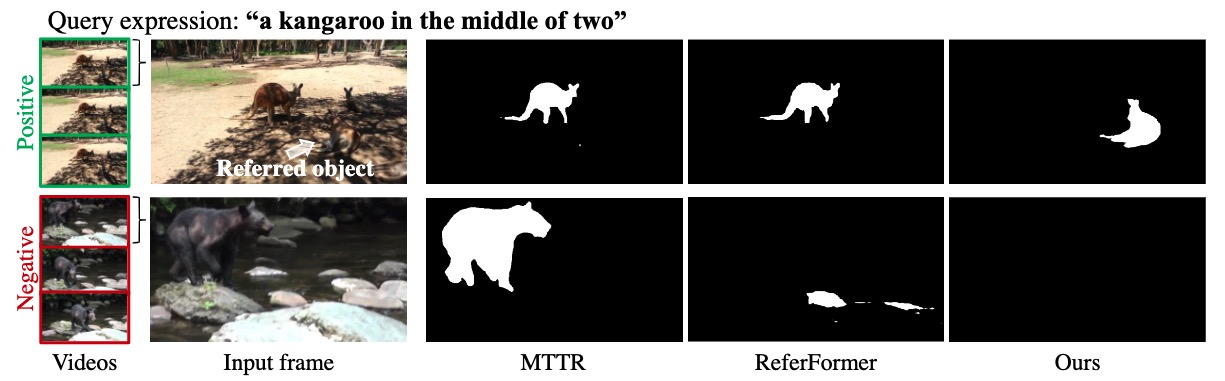
Robust Referring Video Object Segmentation with Cyclic Structural Consensus
Xiang Li, Jinglu Wang, Xiaohao Xu, Xiao Li, Yan Lu, Bhiksha Raj
ICCV, 2023
[paper]
[project page]
[code]
|
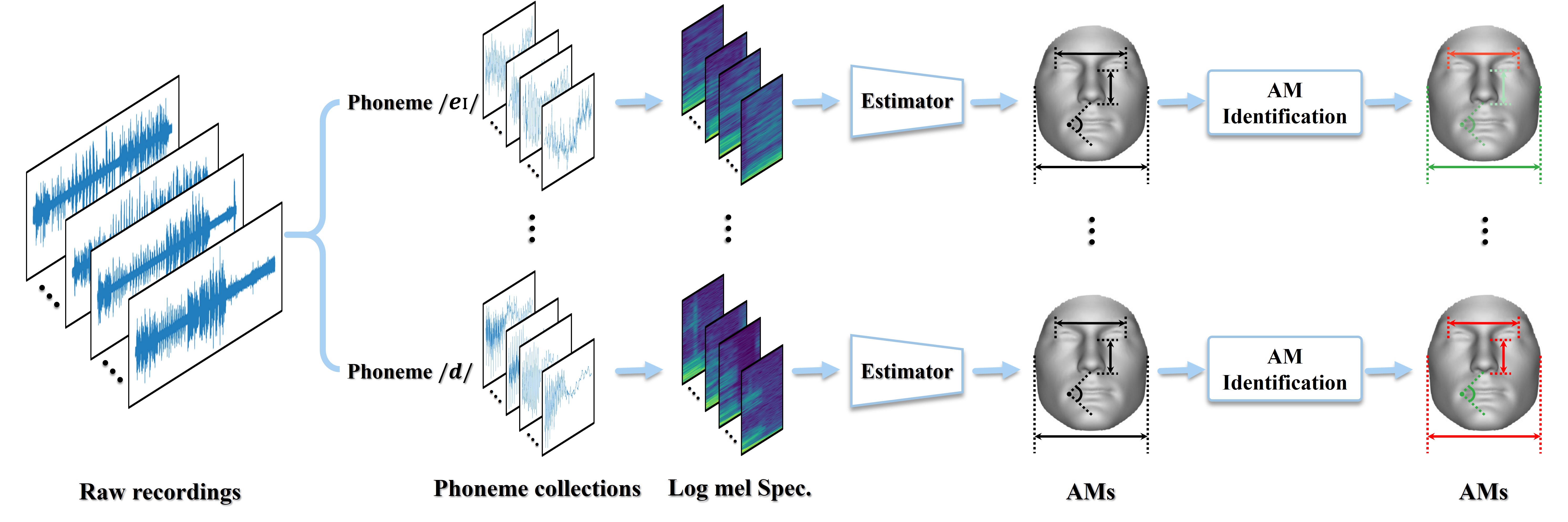
|
The Hidden Dance of Phonemes and Visage: Unveiling the Enigmatic Link between Phonemes and Facial Features
Liao Qu*, Xianwei Zou*, Xiang Li*, Wendong Yan, Rita Singh, Bhiksha Raj
InterSpeech, 2023
[paper]
[code]
|
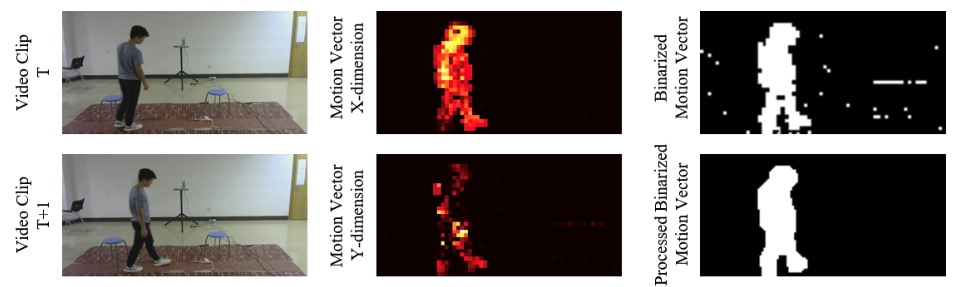
|
Self-supervised Multi-Modal Video Forgery Attack Detection
Chenhui Zhao, Xiang Li, Rabhi Younes
WCNC, 2023
[paper]
[code]
|
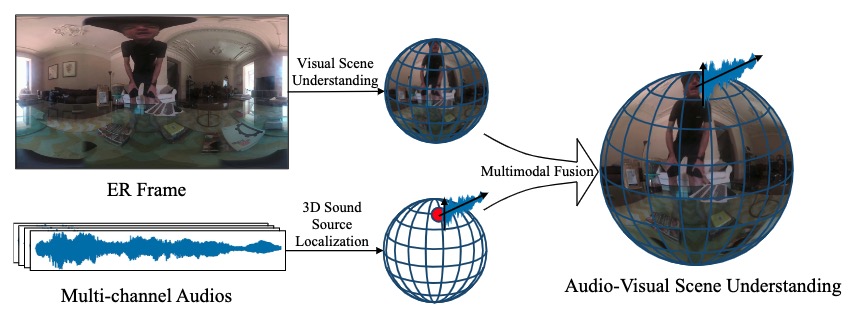
|
Panoramic Video Salient Object Detection with Ambisonic Audio Guidance
Xiang Li, Haoyuan Cao, Shijie Zhao, Junlin Li, Li Zhang, Bhiksha Raj
AAAI, 2023
[paper]
[visualization]
|
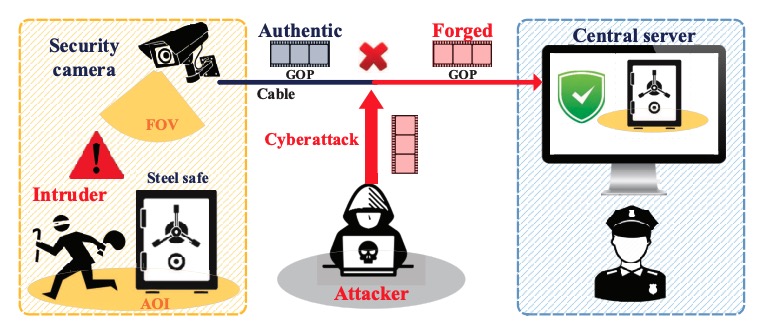
|
Forgery Attack Detection in Surveillance Video Streams Using Wi-Fi Channel State Information
Yong Huang, Xiang Li, Wei Wang, Tao Jiang, Qian Zhang
IEEE Transactions on Wireless Communication
[paper]
|
|
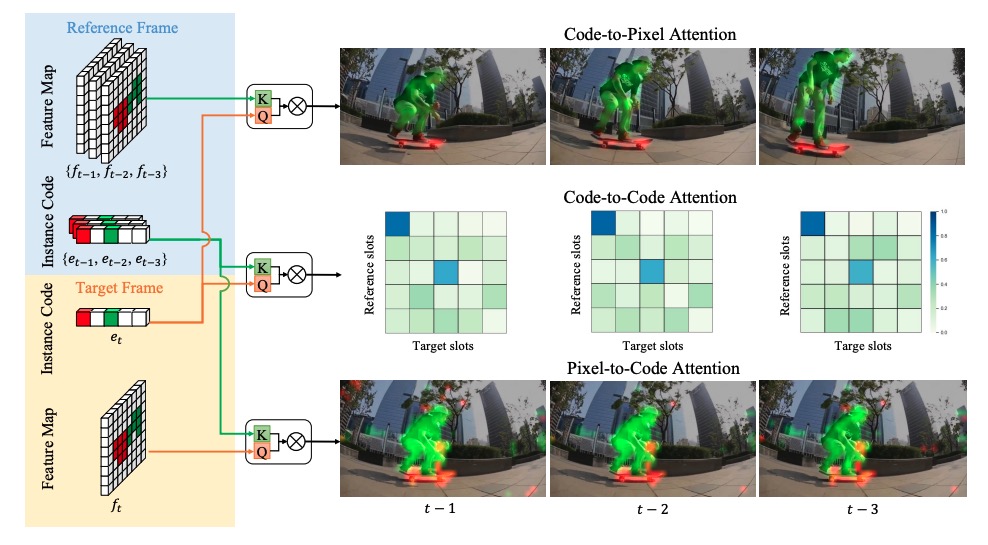
Hybrid Instance-aware Temporal Fusion for Online Video Instance Segmentation
Xiang Li, Jinglu Wang, Xiao Li, Yan Lu
AAAI, 2022
[paper]
|
|
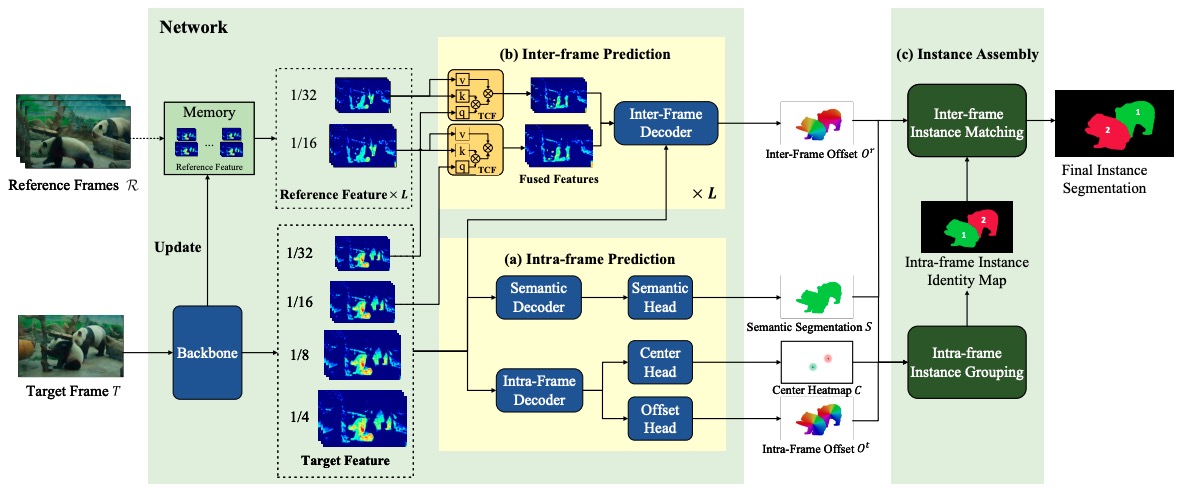
Video Instance Segmentation by Instance Flow Assembly
Xiang Li, Jinglu Wang, Xiao Li, Yan Lu
IEEE Transactions on Multimedia
[paper]
|

|
Towards Cross-Modal Forgery Detection and Localization on Live Surveillance Videos
Yong Huang, Xiang Li, Wei Wang, Tao Jiang, Qian Zhang
IEEE INFOCOM, 2021
[paper]
|
|
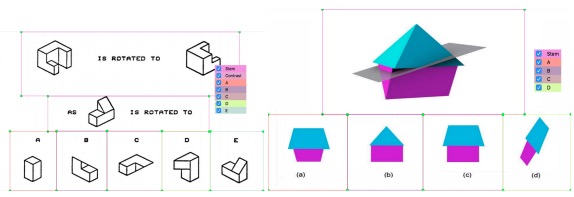
Predicting Spatial Visualization Problems’ Difficulty Level from Eye-Tracking Data
Xiang Li, Rabih Younes, Diana Bairaktarova, Qi Guo
Sensors, 2020
[paper]
|
|
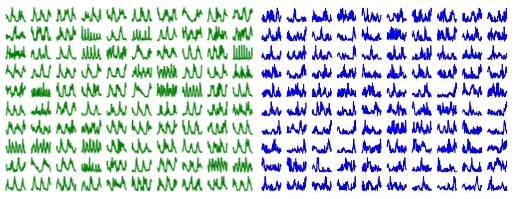
ActivityGAN: Generative Adversarial Networks for Data Augmentation in Sensor-Based Human Activity Recognition
Xiang Li, Jinqi Luo, Rabih Younes
DLHAR workshop @ Ubicomp (Best Paper Award), 2020
[paper]
|
|
Toward Data Augmentation and Interpretation in Sensor-Based Fine-Grained Hand Activity Recognition
Jinqi Luo, Xiang Li, Rabih Younes
ML4HAR workshop @ IJCAI, 2020
[paper]
|
Academic Activities
-
Reviewer
Conference: ICML, ICLR, NeurIPS, CVPR, ICCV, ECCV, EMNLP, NAACL, ACL, AAAI, ACM MM
-
Mentorship
Kai Qiu: MS at CMU (ongoing).
Liao Qu: MS at CMU. Now MLE at Tiktok.
Xianwei Zou: MS at CMU. Now PhD at UC Santa Barbara (UCSB).
Chenhui Zhao: MS at Duke. Now PhD at Duke University.
Zhaorun Chen: MS at Purdue. Now PhD at University of Chicago.
Fan Yang: MS at CMU. Now PhD at Ohio State University (OSU).